適当にかいつまんでいる上に、自身の解釈が混ざっている私的メモです。詳しくは原典を参照してください。
As of 07/03/2018, This paper is under review at ICML 2018.
この論文の要旨
この論文ではDeep Learningによる、画像復元を扱っています。従来の学習手法では、欠損した画像を入力データとして、ターゲットとなる完全な画像が出力になるように、ネットワークをトレーニングします。そのため、学習に際して、欠損した画像と、ターゲットになる完全な画像をペアにした学習データセットを用意する必要があります。
対して、この論文の手法は、ターゲットとなる完全な画像を用意せず、欠損した画像のみを用いて、ネットワークを学習させ、完全な画像をターゲットとした場合と遜色ないパフォーマンスを示す学習結果を達成するものとなっています。
Theoretical background – 理論的背景
例えば、ある部屋の温度を何回か計測し、そこから室温の真値を推定する場合を想定します。ここで考えられる一般的な手法は、あるロス関数(誤差関数)を設定し、その誤差が最小平均偏差となるように、誤差関数のパラメーターを調整する方法です。

E_yはEstimatorで、L()は任意のLoss関数、そして、zがロス関数のパラメーターで、yが入力データとなる計測した温度です。この際、L()を、L2Loss関数とした場合、最小となるzの値は、yの算術平均から求めることができます。そして、zがyの期待値となります。
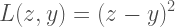
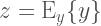
また、L1Loss関数
を採用し場合、zの最適値は、yの中央値となります。

これをニューラルネットワークの学習に置き換えると、以下のようになります。
xが入力データ、yがターゲットとなるデータ、f_theta()がネットワーク関数で、thetaが学習パラメーターとなります。Loss関数が最小化するようにネットワークのパラメーターを調整します。
もし、入力データ間の依存性を取り除き、f_thetaを単なるスカラー値を出力する関数に置き換えたら、この学習タスクは、最初の式と等価になります。
一方で、学習タスク全体を、各入力サンプルごとの最小化問題に分解した場合、上記の式は下記の式と等価になります。
(この式の解釈は、いまだよくわかりません。y|xをxの事後のyと解釈すると、x,yが同時に発生しなくても、学習パラメータthetaを最小化することが可能であると示していると思います。)
ネットワークは、理論的に、入力サンプルごとに単体の推定問題を別々に解決することによって、Lossを最小化することができます。 したがって、ロス関数の持つ基本的な特性は、ニューラルネットワークのトレーニングにおいても継承されます。

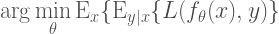
話は変わりますが、一般的なニューラルネットワークの学習において、入力データとターゲットデータは、対になっていると、(誤って)仮定されています。しかし、実際は、一つの入力データーに対して、複数のターゲットデータが存在することが可能な場合があります。例えば超解像の学習などでは、入力データは丸め込まれた低解像度画像なので、それに対応しうる高解像度画像は複数存在することが可能です。この事後確率分布をp(y|x)とします。
低解像度の入力画像から、高解像度のターゲット画像を、L2ロス関数を用いてネットワークに学習させると、ネットワークは、高解像度ターゲットのとりうる値の算術平均を出力するように学習され、結果として、ブラーのかかった画像になってしまう傾向が知られています。
この欠点ともいうべき傾向は実は利点を持っていて、L2最小化による期待値の推定において、ターゲットとなる値を、期待値がターゲットと同一となるランダムな数字で置き換えても、算出される期待値は変わりません。これは最初の室温の推定の式からもわかる通り、観測した温度がどのような分布になっていても、yの算術平均が同じであれば、算出される期待値に影響を与えません。同様に、ネットワークの最適化パラメーターのthetaも、ターゲットデータの事後確率分布p(y|x)がどのような分布になっていても、期待値がターゲットと同一ならば、不変となります。
この事実は、理論的には、平均値がゼロになるノイズを用いて欠損させたターゲットデータを用いて、ネットワークの学習を行っても、ネットワークの学習するものは変わらないということにつながります。
したがって、通常の一般的には、下記のように欠損した入力データ:\hat{x}とターゲットデータ:yで学習しますが、

上記の仮定に基づくと、欠損したターゲットデータ:\hat{y}を用いて学習しても、thetaは変わらないということになります。

そして、入力データの分布と、ターゲットデータの分布が等しい必要すらありません。ただし、以下の条件が必要になります。
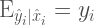
Practical experiments – デモンストレーション
では、実験結果を見ていきます。画像復元に使うネットワークは、RED30[Mao et al, 2016]と呼ばれる、30層のResNetで、いろいろな分野の画像復元で実証されているネットワークです。
Gaussian Noise
まず初めにImageNetのValidation Data Setの個々のターゲット画像にGaussian Noiseをランダムに適用します。ただし平均値がゼロになるように適用します。これを、クリーンなターゲット画像を用いて学習した場合と比較します。学習は5セット行い、それぞれ異なる初期パラメーター(乱数)から学習をスタートします。
結果は、クリーンな学習データで学習したネットワークのValidationにおける平均PNSRが31.63dbであったのに対して、Gaussian Noiseを適用したデータで学習した場合は、31.61dbでした。つまり、Gaussian Noiseを適用したデータでも、等価な学習が行われたといえると思います。学習の過程における収束の速度もほとんど変わりがありませんでした。
さらに、過酷な条件として、Gaussian NoiseにブラーFilter(Low-Pass Filter)をかけて、Pixel間の関連を強めたノイズを導入したターゲット画像を用いてトレーニングした結果が示されています。結果は、Low-Pass Filterの半径が大きくなるにしたがって、ネットワークの学習の進捗が遅くなりますが、Epochを重ねるごとに、最終的には、Low-pass Filterが適用されていない場合と遜色ないパフォーマンスを示すようになります。
Poisson Noise
写真のノイズとしてよく知られる、Poissonノイズでも同様のテストを行っていますが、クリーンなターゲット画像を用いた場合と遜色ないパフォーマンスと収束速度となっています。写真のノイズにおいては、Poissonノイズ以外にも、暗電流ノイズと量子化ノイズがありますが、これらはPoissonノイズと比べると小さく、平均値をゼロにすることができるため[Hasinoff et al.,2016]、Noisyなターゲットを用いて学習する上で問題となりません。
Multiplicative Bernoulli noise
Multiplicative Bernoulli noiseと呼ばれる、ランダムマスクを適用したターゲット画像による学習では、マスクが適用されたPixelからのBackpropagationを避けるため、Loss関数にも同様のマスクを適用して学習させます。この場合は、クリーンなターゲットを用いた場合が、31.85dbだったのに対して、Noisyなターゲットを用いた学習では、32.02dbとなり、Noisyなターゲットを用いた場合のほうが良好なパフォーマンスとなりました。おそらく、ランダムマスクが、Dropoutと同じ効果を果たしたのではないかと、論文著者は考えています。いずれにせよ、興味深い結果となっています。
Text Removal
次に、画像の上にランダムな文字列、色、そしてフォントサイズのテキストをOverlaidさせた入力画像からテキストを取り除く学習を行います。Overlaidさせるテキストの量が多少増えても、基本的にオリジナル画像のPixelが一番多いはずなので、中央値は正しいものとなるはずです。したがって、L1Loss関数を用いて学習します。論文のFig(3)には、実験として、L2,L1,CleanTargetによる学習の結果がそれぞれ示されています。L2で学習したネットワークには、OverlaidさせたTextの色の平均値(Gray)のBiasがかかっているのが見て取れます。
Random-valued impulse noise
いくつかのピクセルを、一様分布のランダムカラーノイズで置き換え他はオリジナルのカラーを保持します。Pixelの分布は、オリジナルのカラーでDiracになり、それにランダムカラーノイズの一様分布をあわせた分布になります。このケースでは、平均も中央値も正しい結果をもたらしません。正しい値は、色の分布のモード(最頻値)となります。(つまりは、DiracのSpike。)分布は、単峰性となります。
最頻値の推定をするために、AnnealedされたL0ロス関数をを用います。
トレーニングの初めは、gamma=2から始め、徐々にgamma=0に向かってLoss関数を変化させながらトレーニングします。fig(4)は、70%のピクセルがランダムカラーノイズで置き換えられた場合のInferenceの結果です。L2を用いたトレーニングでは、グレーにBiasがかかっています。これは、正しい結果と、ランダムカラーの一様分布の平均値の線形合成値となるからです。L1はRandomizedされるPixelが50%以下では良い結果をもたらしますが、これを超えると、明るいPixelと暗いPixelがGrayにBiasされる傾向が出てきます。それに対してL0は、Randomizeされるピクセルが90%以上という極端な場合を除いて良好な結果をもたらします。
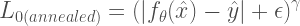
Monte Carlo Rendering
Monte Carlo Integratorは、ランダムパスサンプリングを基本として、サンプリングのノイズは平均ゼロになります。しかしながら、その分布はPixelごとに異なり、シーンやレンダリングのパラメーターに大きく依存し、その特性は多峰性となる場合があります。またいくつかのLightによる影響や、収束したCausticsなどは、非常にLong-Tailな分布を形成し、そのような場所にある明るい輝点は異常値のようにふるまいます。
これらの特性は、Monte Carloによるノイズの除去は、例えばGaussian Noiseの除去よりも難しいものにしています。
一方で、この問題では、データ生成中にクリーンな結果と相関することが経験的に見出された補助情報、例えば、Average Albedo(texture color)や法線ベクトルなどによって多少緩和することができます。この論文では、デノイザーの入力はは、per-pixelのLuminanceだけでなく、Average Albedo(texture color)、そして法線ベクトルで構成されています。
HDR
十分な量のサンプリングをもってしても、PixelのLuminance:vは、かなりの程度で異なる場合があります。そして通常はLuminanceは浮動小数点を用いて表現されます。これを一般的な8bitのディスプレイデバイスで表示するためには、HDRは、トーンマッピングを用いて、ある固定された範囲に圧縮する必要があります。様々なトーンマッピングオペレーターが提案されていますが、今回は、Reinhardのglobal operatorの一種を用います。オペレーターをT(v)とします。
制限のないLuminanceと、非線形のオペレーターであるT()は問題を引き起こします。もし、デノイザーををLuminance:vを出力するように学習させると、L2Loss関数は、Long-Tail Effect(収束したCausticsや、Specular等の輝点)に支配されることになり、学習が収束しません。一方で、トーンマップの出力であるT(v)を出力するように学習すると、T(v)の非線形性が、トーンマッマップしたNoisyなターゲットのT(v)の期待値 

HDR画像の品質評価でしばしば使われる relative MSE(Rousselle2011)がありますが、これも非線形性の問題を抱えています。しかしながら、ネットワークの出力として、制限的に正しい値へ向かう傾向を持ったL_hdrを提唱しています。
L_HDRは、分母のGradientがゼロになっていくと考える限り、正しい期待値に向かって収束します。

さらに、実験的にですが、トーンマッピングした画像を入力として、リニアな画像を出力とした場合のほうが、入力と出力共に、リニアな画像とした場合よりも良好な結果となったそうです。Fig6に、各種Loss関数を用いた場合の比較を載せています。
Denoising Monte Carlo rendered images
いよいよ、レンダリング画像のデノイジングです。64Sppの860枚の建物のレンダリング画像を用いてトレーニングをしました。画像は1枚につき3種類用意し、二つの64sppの画像をnoise2noiseの学習用に、131ksppをクリーンなターゲット画像として、用意しました。さらに、先ほど言った通り、AlbedoとNormalのバッファも生成します。
このように小さなデータセットでも、131ksppのクリーンな画像をレンダリングするのは、大変です。たとえば、Fig(7)のdをレンダリングするのには、40コアのXeonを用いても、40分かかっています。
Validation用のデータセットの、64sppの入力画像のリファレンス画像に対するPSNRの平均は22.31dbです。クリーンなターゲット画像を使った2000Epochの学習は、同様のデータセットで平均31.83dbのパフォーマンスとなっています。
一方で、Noisyなターゲット画像を使った学習では、これより0.5db低い結果となりました。TariningはTeslaP100 を使って12時間かかりました。
さらに学習を進めると、どちらのNetworkもゆっくりと進歩していき、Noisyなターゲット画像を用いた場合では、4000Epoch超えて31.83dbを達成しています。クリーンなターゲット画像を用いた学習に対して、収束するのに2倍の時間がかかりました。
しかしながら、これら2つの方法の間のギャップはかなり狭くならず、これらには何らかの品質差が、(学習における)限界においてもあると、論文著者は信じているそうです。
これは、明らかに想定されることで、なぜなら、トレーニング用のデータセットは、クリーンなターゲット画像を作るコストのため、非常に限られた数のペアしかなく、テストを同じ数のデータセットで行う必要があったからとしています。
(これには、ある程度説得力があると思います。なぜなら、sppの低い画像が持つ情報量は、sppの高い画像のもつ情報量より明らかに少なく、単にノイズの程度の大小ではないからです。)
論文著者も、Noisyなターゲット画像は2000倍速く生成できることから、より多くの学習データを生成し、もっと高いパフォーマンスのネットワークをトレーニングすることは可能であると述べています。
Online taraining
非常に多くのデータセットを用いて、どんなシーンにも対応できるデノイザーを学習することは、非常に難しいです。対して、別の可能性として考えられるのは、デノイザーを単一の3Dシーン、例えば単一のゲームのレベルや、ムービーショットに対して学習することです。この場合では、例えばシーンの中を歩いている間などに、デノイザーを動的に学習させることが望まれます。この際に、フレームレートを保持するために、sppは低い状態としなければならず、入力画像もターゲット画像もNoisyなものとなります。
Fig8は、Noisyなターゲットを用いた場合と、クリーンなターゲットを用いた場合で1000フレームにわたりシーンをFlytroughした際にOnlineでトレーニングした際のPSNRのプロットになっています。
Titan Vを用いたテストでは、8sppの512sqの画像をレンダリングするのに190msかかっており、2枚の画像をレンダリングし、入力とターゲットとして各々を使っています。1回のネットワークの学習イテレーションはは、256sqにcropした画像を用い、11.25msかかっています。これをフレームごとに8回行っています。最後に15msかけてデノイジングの処理を行っています。そして最終結果をユーザーに表示するようになっており、1フレームあたり、全体で500msかかる処理となっています。
対して、クリーンなターゲット画像を用意した場合1フレームあたり7分の処理となっています。そして、Fig8でわかる通り、Noisyなターゲットとクリーンなターゲットを使って学習した場合に有意な差は認められません。
MRI
割愛
感想
初見では、とにかくNoisyなデータセットをターゲットにして学習してもうまくいくと解釈していましたが、論文をある程度読んだ後では、何となくですが仕組みがわかりました。そしてこれが適用できる分野は画像処理にとどまらず色々考えられるのではないかと思います。ターゲットとしたいデータとそれに含まれるノイズの傾向が分かっていて、かつ、自分が何を出力したいのかが理解できていれば、本手法が適用できるかどうかが自ずとわかるのかなと思います。
